Integramos scripts en R en nuestros cuadro de mando y dashboards de Tableau.
El pasado mes de octubre presentamos un interesante webinar sobre cómo integrar R y Python en la plataforma Power BI (y además con su propio hashtag #PoweR-Py). En este post os contamos cómo integrar la herramienta más utilizada para los analistas de datos, estadísticos y expertos en data mining, con la otra competidora de las herramientas de visualización de inteligencia de negocio, Tableau.
¿Por qué utilizar R en las herramientas de visualización Tableau?
R es un lenguaje de análisis estadístico de código abierto. Aquí puedes ver pequeños tutoriales y casos de uso con este lenguaje en su propio entorno de R Studio, por ejemplo, analizando tendencias, clustering y Market Basket Analysis.
La gran mayoría de casos de usos se extendieron en los años noventa, principalmente en el entorno universitario, y llegando hasta los entornos de producción de bancos, seguros y muchas empresas.
Con el avance de la era Big Data y la visualización de información en las empresas para la toma de decisiones, ha ido creciendo la necesidad de realizar operaciones con entornos tales como SAS, Stata, R o Python sobre las propias herramientas que aportan la visualización (como Tableau) para poder aprovechar al máximo las posibilidades de estos lenguajes, tanto para recogida de datos, transformación, limpieza y preparación para, posteriormente, poder realizar tareas típicas de un analista de datos, minería de datos y Machine Learning, visualización y descubrimiento de nuevos insights.
Dentro del entorno de Tableau, podemos utilizar R a través de campos calculados y aprovechar los beneficios que brindan las funciones, bibliotecas y paquetes este lenguaje. Estos cálculos invocan dinámicamente el motor R y pasan valores a través del paquete Rserve (como veremos más adelante), devolviendo así los resultados calculados a Tableau. Esta integración de R con Tableau aprovecha las capacidades analíticas estadísticas de R con el poder de visualización típica de estas herramienta “arrastrar - soltar”, como el caso de Tableau.
Preparar el terreno de juego: entornos
Es importante entender el funcionamiento desde el principio, ya que puede constar enfocarlo. Normalmente, un analista de negocio (o bien un analista de datos) suele trabajar en local, donde realiza sus operaciones a través de varias herramientas interconectadas a la base de datos, repositorios en Cloud, etc. Lógicamente utilizaremos R Studio (la tool con capa visual que para el lenguaje R), para poder crear este vínculo. La realidad es que Tableau Server, la aplicación versión enterprise en la nube, se conectaría con R Server para que todo esté en la nube, securizado y sin depender de nuestro ordenador, con sus limitaciones.
Requisitos a tener en cuenta:
- Tableau Deskop: obviamente no podemos depender de una una versión free, como la Public, así que en el caso de que no tengas la versión de pago, puedes aprovechar el free-trial de 15 días (para este caso de uso y el siguiente de Python estaría bien). Está disponibile tanto para Windows que MacOS
- R / R commander: es el motor de R, por lo que instalaremos su versión última tanto en Windows / MacOS o su alternativa a través de la tool de análisis y ciencia de datos, Anaconda (aunque personalmente no la recomiendo por su peso excesivo e innecesario).
- R Studio: la tool de gestión de R en manera más cómoda, entorno amigable y donde podemos aprovechar al máximo nuestras tareas de minería de datos y análisis. Además, es open source y free.
Instalamos los paquetes necesarios en R Studio
Simplemente nos situamos en Packages y efectuamos la instalación de Rserve, el motor que nos sirve de comunicación con Tableau.
La manera manual de instalar un paquete también puede ser efectuado por código:
# Instalamos Rserve
install.packages("Rserve")
# Cargamos la librería
library(RServe)
# Ejecutamos la sección de ayuda y comprobar sus funciones
help(RServe)
# Ejecutamos para su comprobación
Rserve()
Copy.
En caso de que tengas error con este último comando, especialmente si estás en MacOS, es probable que debas utilizar este comando para ejecutarlo:
# Ejecutamos Rserve en Mac OSx
Rserve::run.Rserve()
# El resultado en consola será:
>> running Rserve in this R session (pid=xxxx), 1 server(s) --
(This session will block until Rserve is shut down)
Copy.
En este punto R Studio se quedará abierto y enviará todas sus informaciones a Tableau. Acuérdate de no cerrar la sesión de R durante la práctica con Tableau porque si perdemos la conexión ya no podemos ejecutar las funciones.
Abrimos Tableau Desktop y seguimos con los pasos indicados:
- Vamos en la sección Help tal como en la captura:
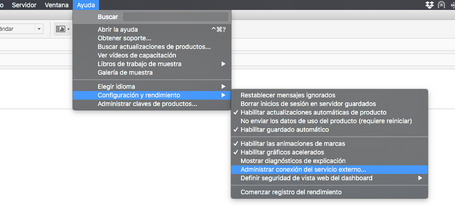
- Seguimos los mismos pasos indicados y probamos la conexión:
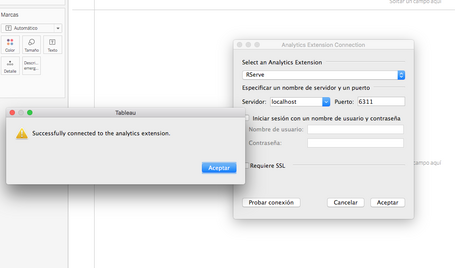
Ahora podemos utilizar unas funciones que sin R ni Python sería imposible usar.
Explicación de las funciones de tabla
Existen 4 funciones principales asociadas a la categoría Funciones de cálculo de tablas, especiales para la conexión con R y Python y son:
- SCRIPT_STR: Indica un resultado de cadena de la expresión especificada. La expresión se pasa directamente a una instancia de extensión de análisis en ejecución. En las expresiones R utilizamos .argn (con un punto inicial) para hacer referencia a parámetros (.arg1, .arg2, etc.). En las expresiones de Python, utilice _argn (con un guión bajo inicial).
- SCRIPT_BOOL: Indica un resultado booleano de la expresión especificada. La expresión se pasa directamente a una instancia de extensión de análisis en ejecución. En las expresiones R usamos .argn (con un punto inicial) para hacer referencia a parámetros (.arg1, .arg2, etc.). En las expresiones de Python, _argn (con un guión bajo inicial).
- SCRIPT_REAL: Indica un resultado con un valor numérico real de la expresión especificada. La expresión se pasa directamente a una instancia de extensión de análisis en ejecución. En las expresiones R utilizamos .argn (con un punto inicial) para hacer referencia a parámetros (.arg1, .arg2, etc.). En las expresiones de Python, _argn (con un guión bajo inicial).
- SCRIPT_INT: Indica un número entero como resultado de la expresión especificada. La expresión se pasa directamente a una instancia de extensión de análisis en ejecución. En las expresiones R, .argn (con un punto inicial) para hacer referencia a parámetros (.arg1, .arg2, etc.). En las de Python, _argn (con un guión bajo inicial).
Para estas cuatro funciones utilizaremos las muestras de ejemplo Sample-Superstore.xlsx que viene por defecto en nuestro Tableau. Sucesivamente cargaremos otros dataset de ejemplo directamente desde R Studio.
Demo con la función SCRIPT_STR()
En esta demo veremos el uso más sencillo de esta función: cómo realizar una extracción del campo “name”. Una vez efectuada la conexión en R, abrimos un nuevo proyecto y cargamos el dataset de ejemplo. Sucesivamente creamos el primer campo calculado:
# CustFirstName
SCRIPT_STR(
'
substr(.arg1, 1, regexpr(" ", .arg1) -1
'),
ATTR([Customer Name])
Copy.
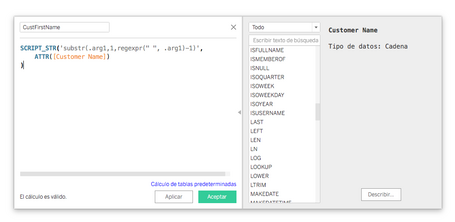
Vemos en nuestro código que la función SCRIPT_STR llama a la función substr en R con “Customer Name” como argumento 1 y extrae caracteres de “Customer Name”, comenzando en la posición de carácter 1 hasta la primera aparición de espacio.
La función substr() se utiliza para recuperar o reemplazar una subcadena de una cadena de caracteres. La sintaxis de la función es la siguiente:
substr (x, start, stop) donde:
- x - una cadena de caracteres.
- inicio - la posición del índice en la que debe comenzar la extracción de caracteres.
- stop - número de caracteres para devolver.
La función ATTR() en Tableau devuelve el valor de la expresión dada si todas las filas del grupo tienen SOLO un valor único; de lo contrario, devuelve un asterisco (*). Los valores nulos se ignoran.
Visualizamos en Tableau
Una vez realizada la creación del campo calculado procedemos a utilizarlo en nuestro dashboard. Arrastramos la dimensión Customer Name en filas y la medida creada en la columna:
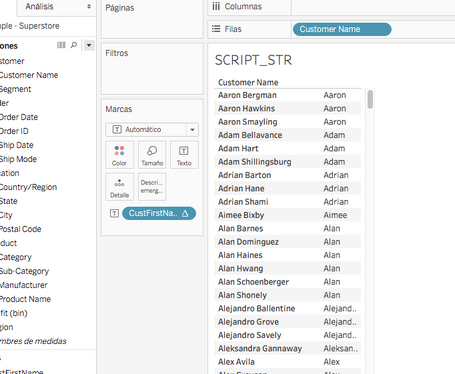
Demo con la función SCRIPT_BOOL()
Con el mismo dataset anterior, en fila añadimos las dimensiones State y City. Arrastramos Sales y obtenemos lo siguiente.
Creamos ahora el nuevo campo calculado con STR_BOOL
# StateMinnesota
SCRIPT_BOOL(
'
grepl("Minnesota", .arg1, perl=TRUE)
',
ATTR([State])
)
Copy.
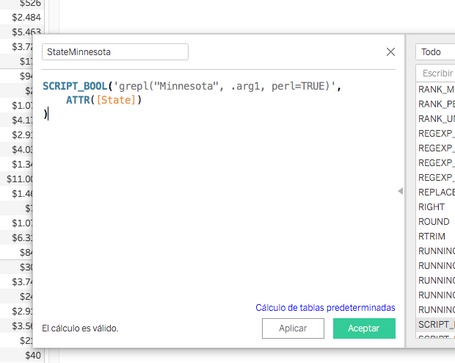
La función SCRIPT_BOOL llama a la función “grepl” en R, que evalúa el atributo “Estado” y devuelve “TRUE” si el atributo “Estado” tiene el valor “Minnesota”.
Si la cadena contiene el patrón, la función grepl devuelve VERDADERO; de lo contrario, devuelve FALSO. Si el parámetro resulta ser un vector de cadena, la función devuelve un vector lógico (VERDADERO si es una coincidencia, de lo contrario FALSO). La sintaxis de la función:
grepl (patrón, x, ignore.case = FALSE, perl = FALSE, fixed = FALSE, useBytes = FALSE)
Copy.
patrón: expresión regular o cadena para fijo = VERDADERO
x: string, el vector de caracteres
ignore.case: distingue entre mayúsculas y minúsculas o no
perl: lógico. ¿Deben usarse expresiones regulares compatibles con Perl?
fijo: lógico. Si es TRUE, el patrón es una cadena que debe coincidir tal cual. Anula todos los argumentos en conflicto
useBytes: lógico. Si es TRUE, la coincidencia se realiza byte a byte en lugar de carácter a carácter
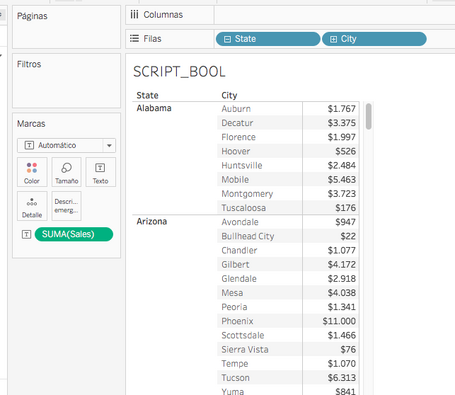
Visualizamos en Tableau
Podemos utilizar el cuadro de mando anterior, el campo calculado e insertarlo en filtros. Veamos el resultado final teniendo en cuenta de seleccionar TRUE y su comportamiento con FALSE:
Demo con SCRIPT_REAL()
Para el uso de esta función utilizamos un dataset para realizar multiregression, US-Census, está disponible en este repositorio (es el mismo para descargar el resto de demos realizadas). Haremos uso de parámetros what-if y veamos cómo emplearlo en este ejemplo. Pasamos solo un subconjunto de filas pasadas desde Tableau en R.
El resultado de la predicción es un valor único, que usamos para anular el número de inscripción desconocido (representado como un valor nulo en Tableau) para el año 2013.
Hay que tener en cuenta que todo (medidas, dimensiones, parámetros, constantes) se pasa como vectores a R. Entonces, si su cálculo necesita escalar, simplemente puede obtener el primer elemento del vector usando [1].
- Por ejemplo, nuestro .arg5 es un parámetro que está vinculado al desempleo. Lo estamos usando como .arg5 [1] para leerlo como un valor único / escalar en nuestro cálculo. Dependiendo del cálculo, leerlo como escalar .arg5 [1] vs vector .arg5.
- Puede devolver resultados diferentes. Para estar seguro, es mejor usarlos como escalares si sabe que su cálculo necesita escalar.
SCRIPT_REAL("
# Creamos un dataset con 4 argumentos
mydata <- data.frame(cbind(Enrollment=.arg1, HighSchoolGrads=.arg2, PerCapitaIncome=.arg3, Unemployment = .arg4))
# Creamos linear modeling
fit <- lm(Enrollment[-29] ~ HighSchoolGrads[-29] + PerCapitaIncome[-29]+ Unemployment[-29],data=mydata); mydata$Enrollment[29]<-predict(fit,list(HighSchoolGrads= .arg7[1], PerCapitaIncome = .arg6[1],Unemployment = .arg5[1]));mydata$Enrollment",SUM([Enrollment]),SUM([HighSchoolGrads]),SUM([PerCapitaIncome]),SUM([Unemployment]),[What If - Unemployment],[What If - Income],[What If - Graduates] )
Copy.
Y el resultado es este:
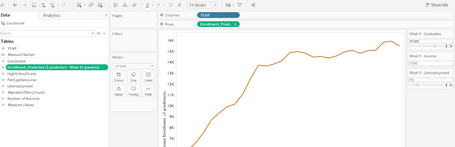
Resumiendo, realizamos cálculos basados en parámetro.
Demo con SCRIPT_INT()
En esta demo utilizaremos el dataset de iris, muy conocido para los amantes de la minería de datos y Machine Learning, disponible en este repositorio. Creamos las agrupaciones por clusters, por lo tanto, 4 campos calculados:
- Clúster de pétalos y sépalos
# Creamos 3 clusters
SCRIPT_INT(
'
set.seed(42);
result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4), 3);
result$cluster;
',
SUM([Petal length]),
SUM([Petal width]),
SUM([Sepal length]),
SUM([Sepal width]))
Copy.
- Total de la suma de los cuadrados:
# Total de la suma de los cuadrados
SCRIPT_REAL(
'
set.seed(42);
result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4), 3);
result$totss
',
SUM([Petal length]),
SUM([Petal width]),
SUM([Sepal length]),
SUM([Sepal width]))
Copy.
- Creamos el centroide del clúster del ancho de los pétalos:
# centroide ancho pétalo
SCRIPT_REAL(
'
library(plyr);
set.seed(42);
result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4), 3);
centers <- data.frame(result.cluster=row.names(result$centers),result$centers);
join(data.frame(result$cluster)[1], centers, by = "result.cluster")[,3]
',
SUM([Petal length]),
SUM([Petal width]),
SUM([Sepal length]),
SUM([Sepal width]))
Copy.
- Creamos el centroide del clúster del largo de los pétalos:
# centroide largo pétalo
SCRIPT_REAL(
'
library(plyr);
set.seed(42);
result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4), 3);
centers <- data.frame(result.cluster=row.names(result$centers),result$centers);
join(data.frame(result$cluster)[1], centers, by = "result.cluster")[,2]
',
SUM([Petal length]),
SUM([Petal width]),
SUM([Sepal length]),
SUM([Sepal width]))
Copy.
Visualización final
En la visualización incluimos los dos grupos de clústeres y el total de la suma de los cuadrados:
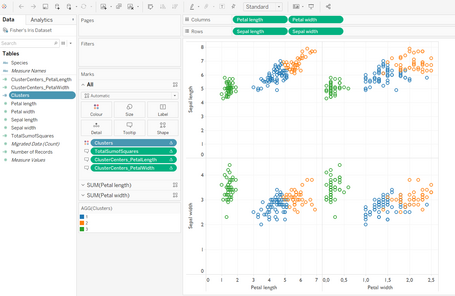
Primero añadimos tanto pétalo como sépalo en columnas y filas respectivamente y seguimos con insertar los 4 campos calculados:
- Clúster en colores.
- Total suma de cuadrados, centroide largo del pétalo, centroide ancho del pétalo en tooltips que serán nuestras etiquetas a mostrar para cada observación.
Resumen
El uso de los campos calculados de Tableau nos ayuda a llevar nuestros informes al siguiente nivel. Con la integración de script en R, podemos realizar tareas que estamos acostumbrados a realizarlas en R Studio con una interfaz y combinaciones de opciones a un nivel más alto.
Si durante la práctica te sientes perdido es lógico. El lenguaje R no es sencillo, y quizás deberías comenzar con algo más básico de estadística y probabilidades con tutoriales de R básico, para ir subiendo de nivel y, finalmente, utilizar otra herramienta que pueda aprovechar estas funciones avanzadas.
¿Has realizado algún cálculo en R y has probado a integrarlo en Tableau? Si es así, puedes comentar en este mismo post y abrir un debate. Y si te ha entrado ganas de conocer cómo funciona con Python con su #TabPy nativo, no puedes perderte el próximo post que hablaré sobre esta integración.
Si quieres aumentar aún más la comprensión de esta increíble herramienta de informes, consulta nuestro canal de YouTube y de los webinar realizados y/o futuros.