Cómo crear una solución de propensión de compra utilizando BigQuery ML y Kubeflow
El caso de uso de propensión de compra es ampliamente aplicable a muchos sectores, comenzando obviamente de retail, finanzas, seguros y que afecta directamente a logística, compras, producción y por supuesto al departamento de marketing. En casi todos los programas de máster de Data Science se enseña mucha práctica sobre modelos de aprendizaje automático, pero teóricamente se ven pocos casos de como aplicarlos, ahí viene el reto de todos estudiantes que recién acaban un bootcamp en Neoland estudiar los diferentes pipeline de machine learning y así meter en práctica lo estudiado y finalmente entender que viene después de crear un modelo en su propio ordenador local.
En este post, explico cómo crear una solución de inicio a fin con BigQuery ML y Kubeflow Pipelines, una herramienta de flujo de trabajo de operaciones de aprendizaje automático que en este ejemplo utilizaremos el notebook oficial de Google Cloud Platform utilizando un conjunto de datos de Google Analytics para determinar qué clientes tienen la propensión a comprar. La idea es de poder utilizar la solución para llegar a tus clientes objetivo en una campaña online y también offline, como también resto de campañas de digital marketing. Es un ejemplo que he realizado y que está actualmente en fase de beta en un cliente y que los estudiantes del bootcamp de Data Science en Neoland están estudiando, para que puedan usarlo cuando el cliente está navegando en un sitio web de comercio electrónico y así, paralelamente crear un recomendador de algunos productos o enviar un correo electrónico personalizado al cliente.
Según un estudio realizado por McKinsey, el saber utilizar correctamente un caso de uso de personalización de campañas y perfilado de usuario, permite a las empresas crear entre 1 y 3 billones de dólares de facturado adicional. Aunque existen en la actualidad empresas que se encargan de recoger datos de los usuarios, (siempre cumpliendo con la RGPD), no siempre son eficientes ni generan un retorno esperado. Los modelos de propensión son importantes ya que son claves para el éxito de la atención de los cliente, utilizados correctamente pueden dirigirse de manera más eficaz a los clientes que tienen más probabilidades de comprar determinados productos.
IMAGEN DE PORTADA COMPRA ONLINE**
Una arquitectura de solución de inicio a fin y pasos de implementación habituales
Veámos como funciona el todo. Primero debemos seleccionar los atributos, crearremos una etiqueta de clasificación (le indicamos si un cliente tiene la propensión a comprar), crearemos un modelo, el modelo lanzará su decisión y predicción en BigQuery con BigQuery ML. Si nunca has utilizado GCP no te preocupes, existen muchos ejemplos útiles y como crear modelos de aprendizaje automático en BigQuery mediante consultas SQL estándar. Esto significa que no necesita exportar sus datos para entrenar e implementar modelos de aprendizaje automático; al entrenar, también está implementando en el mismo paso. En combinación con el escalado automático de los recursos informáticos de BigQuery, no tendrás que preocuparse por hacer girar un clúster o crear una canalización de implementación y entrenamiento de modelos. Esto significa que ahorrará tiempo en la creación de su canal de aprendizaje automático, lo que permitirá que su empresa se centre más en el valor del aprendizaje automático en lugar de dedicar tiempo a configurar la infraestructura.
Para automatizar este proceso de creación de modelos, se utilizará un organizador mediante Kubeflow Pipelines, una plataforma para la creación e implementación de dispositivos portátiles, flujos de trabajo escalables de aprendizaje automático (ML) basados en contenedores Docker.
Aquí el esquema completo de la arquitectura a realizar:
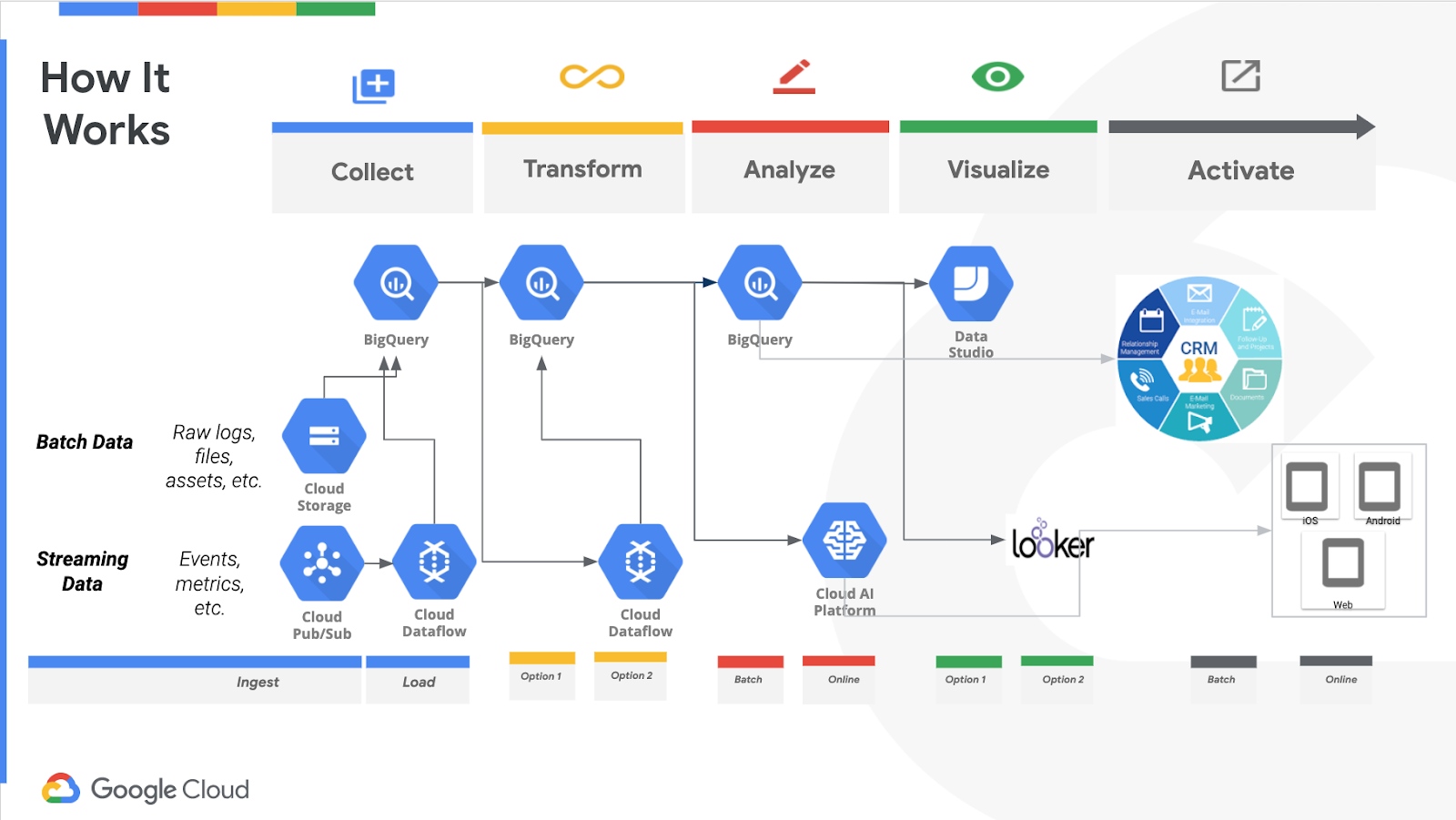
La solución implica los siguientes pasos:
- Identificar la fuente de datos con el historial de compras de clientes anteriores y cargar los datos en BigQuery.
- Preparar los datos para las tareas de Machine Learning (ML).
- Crear un modelo de aprendizaje automático que determine la propensión de un cliente a comprar
- Unificar a los datos del cliente con un sistema CRM para recopilar detalles del cliente (por ejemplo, identificación de correo electrónico, otras informaciones del cliente, etc.)
- Determinar qué producto deberíamos recomendar al cliente
- Lanzar una campaña digital con los datos anteriores (o utilizar este modelo junto con la API de Google Ads, Facebook Ads, etc.)
- Gestionar el ciclo de vida de la comunicación con el cliente (por ejemplo, correo electrónico) en el CRM o similar.
- Redefinir el valor de vida útil del cliente a partir del resultado de la campaña.
- Monitorear los modelos para asegurarse de que cumplan con las expectativas.
- Volver a entrenar el modelo, si es necesario, basándose en un nuevo conjunto de datos o en un conjunto de datos rectificado
Todos estos pasos serán explicados a continuación y aquí el link con el notebook oficial para realizar los 3 primeros pasos de esta solución, evidentemente no pude insertar datos del CRM.
1. Identificar la fuente de datos con el historial de compras de clientes anteriores y cargar los datos en BigQuery.
Dependiendo donde se encuentren los datos en tu empresa, debemos determinar las mejores técnicas de preprocesamiento para llevar los datos a BigQuery. Podemos automatizar el preprocesamiento en una canalización de MLOps, que veremos más adelante. Para este ejemplo utilizaré solo el conjunto de datos alojados en BigQuery, que proporciona 12 meses (agosto de 2016 a agosto de 2017), son datos de Google Analytics 360 de Google Merchandise Store, una tienda de comercio electrónico real que vende productos con la marca Google.
Captura de la tienda Google Merchandise Store.
Y una muestra de consulta estandár con nuestro dataset de ejemplo de Google Analytics:
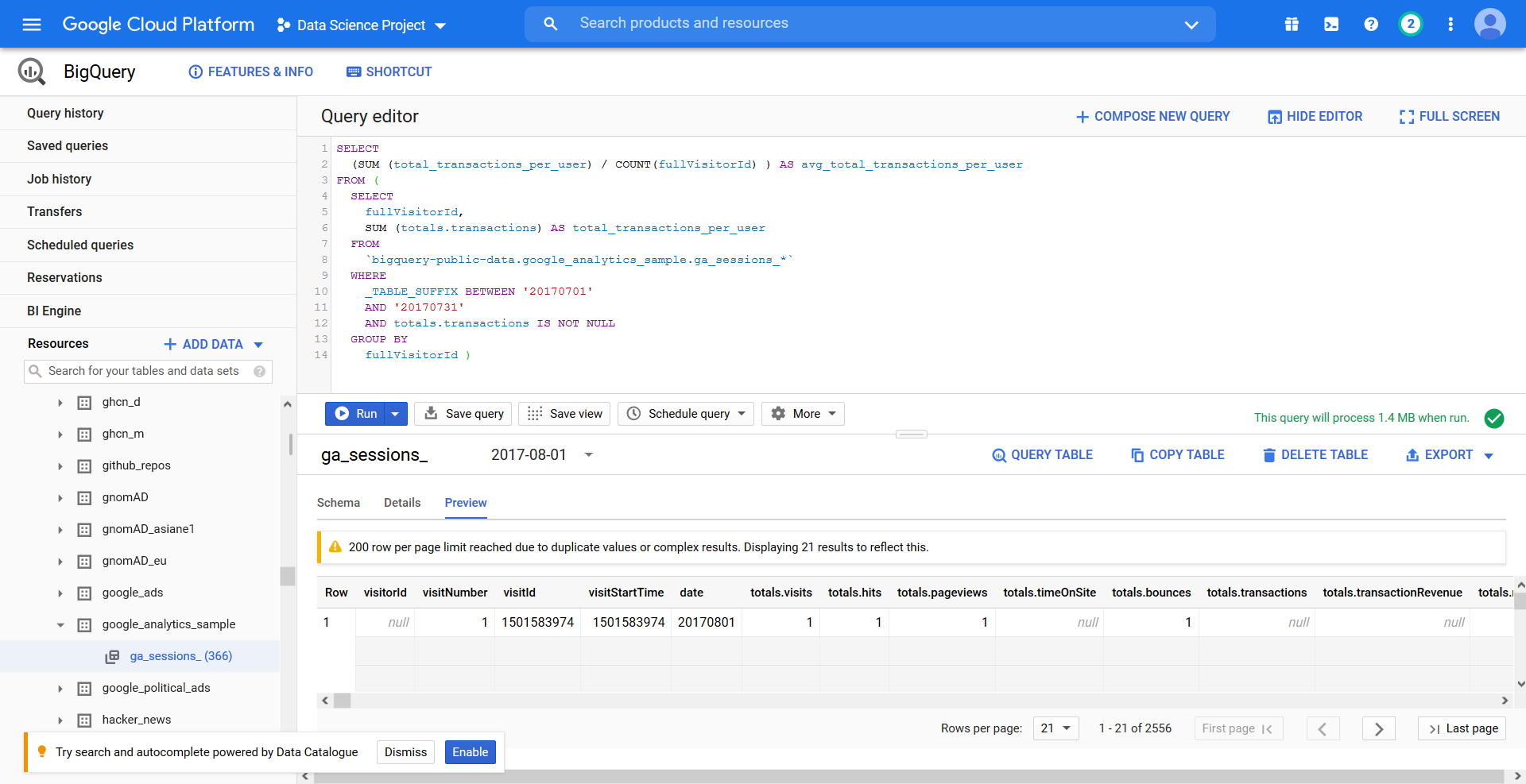
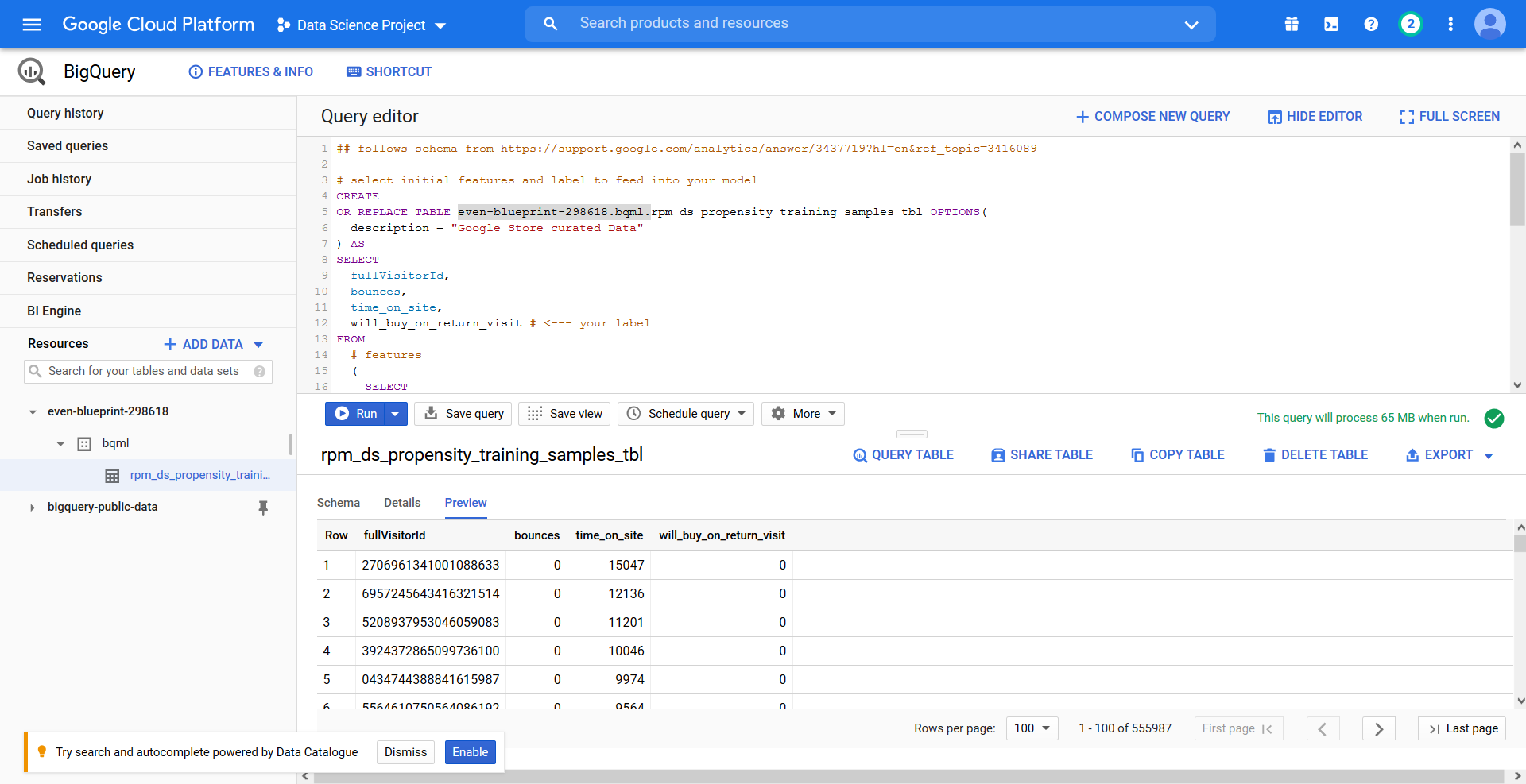
2. Preparar los datos para las tareas de Machine Learning (ML).
Ahora que tenemos el conjunto de datos, comenzamos a preparar los datos para el desarrollo del modelo de ML. Seleccionamos los atributos (las variables indipendientes) y las etiquetas adecuadas si deseamos realizar el aprendizaje supervisado. Para este artículo, utilizaré un par de atributos con fines de demostración y solo utilizando SQL.
La query creará una tabla para entrenar el modelo, con los atributos tasa de rebote y tiempo de sesión, (bounces, time_on_site) y la etiqueta will_buy_on_return_visit que utilizaremos para crear el modelo después:
## follows schema from https://support.google.com/analytics/answer/3437719?hl=en&ref_topic=3416089
# select initial features and label to feed into your model
CREATE
OR REPLACE TABLE even-blueprint-298618.bqml.rpm_ds_propensity_training_samples_tbl OPTIONS(
description = "Google Store curated Data"
) AS
SELECT
fullVisitorId,
bounces,
time_on_site,
will_buy_on_return_visit # <--- your label
FROM
# features
(
SELECT
fullVisitorId,
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
totals.newVisits = 1
AND date BETWEEN '20160801'
AND '20170430'
) # train on first 9 months
JOIN (
SELECT
fullvisitorid,
IF(
COUNTIF(
totals.transactions > 0
AND totals.newVisits IS NULL
) > 0,
1,
0
) AS will_buy_on_return_visit
FROM
`bigquery-public-data.google_analytics_sample.*`
GROUP BY
fullvisitorid
) USING (fullVisitorId)
ORDER BY
time_on_site DESC # order by most time spent first
Aquí el resultado:
3. Crear un modelo de aprendizaje automático que determine la propensión de un cliente a comprar
¿Qué tipo de modelo debemos utilizar? ¿Cuáles son todas las variables indipendientes a utilizar? ¿Cuál debería ser el conjunto de hiperparámetros para el modelo? Aquí llega el momento de meter en prácticas vuestras habilidades y capacidades de científicos de datos.
En este tercer paso debemos clasificar si un cliente tiene la propensión a comprar. Por tanto, es una tarea de clasificación, y siendo un modelo de uso común, utilizaremos la regresión logística que con BigQuery ML lo tenemos identificado en la documentación oficial.
La query será similar a esta:
CREATE
OR REPLACE MODEL `bqml.rpm_bqml_model` OPTIONS(
MODEL_TYPE = 'logistic_reg', labels = [ 'will_buy_on_return_visit' ]
) AS
SELECT
*
EXCEPT
(fullVisitorId)
FROM
`even-blueprint-298618.bqml.rpm_ds_propensity_training_samples_tbl`
Una vez creado el modelo, podemos verificar qué tan bien se comporta el modelo según ciertas reglas. Hemos adoptado algunas reglas empíricas (por ejemplo, ROC-AUC> 0.9) pero podemos ajustarlas según nuestras necesidades específicas.
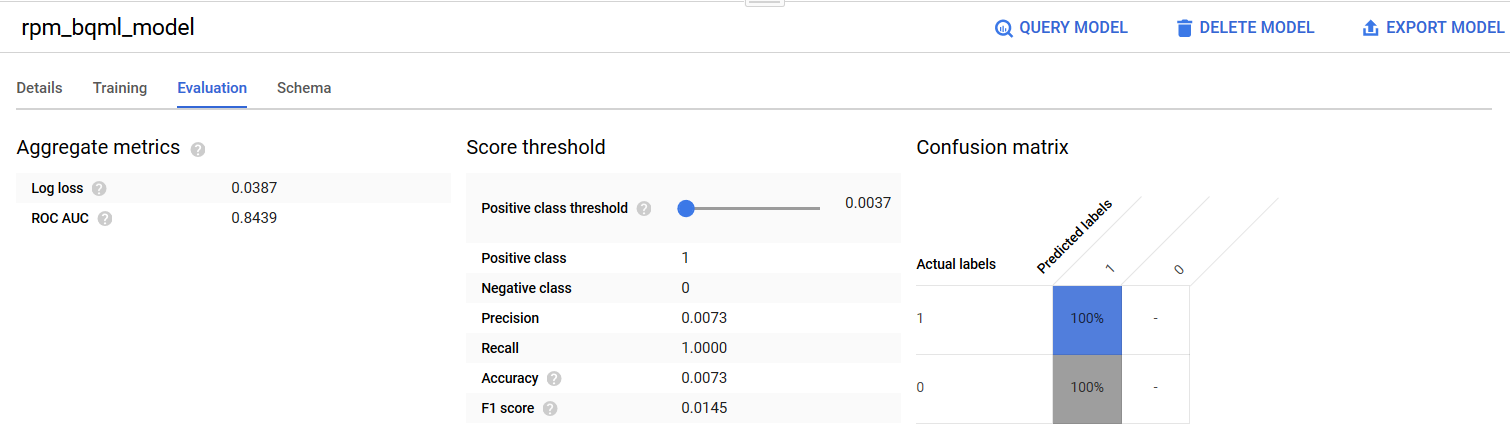
La query evaluará el modelo según el valor esperado ROC AUC:
SELECT
roc_auc,
CASE WHEN roc_auc >.9 THEN 'good' WHEN roc_auc >.8 THEN 'fair' WHEN roc_auc >.7 THEN 'decent' WHEN roc_auc >.6 THEN 'not great' ELSE 'poor' END AS modelquality
FROM
ML.EVALUATE(MODEL `bqmls.rpm_bqml_model`)
El resultado será el siguiente:
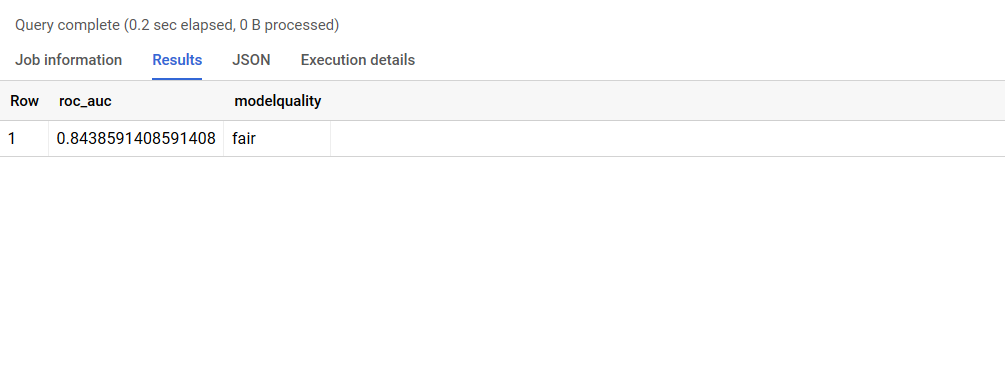
¿Estámos logrando construir un buen modelo? No es fácil contestar simplemente observando un solo resultado, la curva de ROC en este ejemplo, así que lo más probable es que no… Porque el ROC_AUC del 84% se considera un scoring decente, pero no óptimo(http://gim.unmc.edu/dxtests/roc3.htm). Se necesita mucho conocimiento del sector, ajuste de hiperparámetros, features engineering, quizás tareas de preparación y limpieza previa, creación de nuevos atributos, estudio de correlaciones, etc. para construir un buen modelo. Este no es el mejor modelo que podamos crear, pero tenemos una línea de base. Como el objetivo de este artículo es crear una canalización de un extremo a otro en lugar del rendimiento del modelo, el ajuste fino del modelo está fuera del alcance de este artículo.
El modelo entrenado podrá ayudarte a llegar a tus clientes en una campaña tanto offline que campañas de marketing online. Así que usaremos la predicción por lotes (batch) para el primero y la predicción en línea (streaming) para el último. Además, aprovechando la plataforma de GCP, podemos usar el modelo entrenado para la predicción por lotes de un conjunto de datos grande en BigQuery, o implementar el modelo en Google Cloud AI Platform para la predicción en línea.
3a. Utilizar el modelo para la predicción en lotes
Para el escenario de campaña en modo offline, podemos realizar predicciones por lotes asincrónicas en un conjunto de datos grande. Creamos una tabla en BigQuery e insertamos todas los datos de entrada para las que deseamos predecir. Se creará una tabla rpm_ds_propensity_prediction_input_tbl en BigQuery, con cada fila como un cliente con rebotes y características de tiempo en el sitio. Luego, utilicemos el modelo entrenado para predecir todas las entradas / filas.
La query será la siguiente:
# predict the inputs (rows) from the input table
SELECT
fullVisitorId, predicted_will_buy_on_return_visit
FROM
ML.PREDICT(MODEL bqml.rpm_bqml_model,
(
SELECT
fullVisitorId,
bounces,
time_on_site
from `even-blueprint-298618.bqml.rpm_ds_propensity_training_samples_tbl`
))
El resultado de esta query será similar a esta con el resultado 1 para aquellos visitantes que comprarán en la próxima sesión:
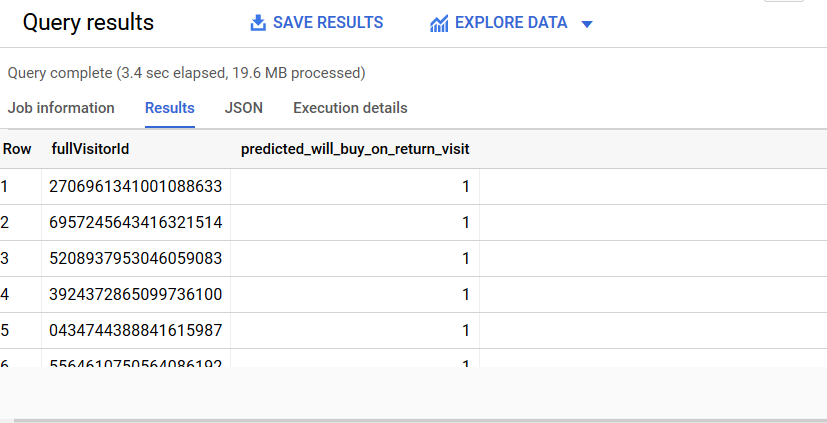
¿Crees que el modelo predice correctamente? Tal vez. Sin duda, necesitamos profundizar más. Es posible que deseamos verificar las características, los parámetros, el umbral, que en este ejemplo es de 0.5 por defecto en el ML.PREDICT anterior, etc. y para ajustar el modelo.
3c. Utilizar el modelo para la predicción online
Para el escenario de la campaña en línea, necesitamos implementar el modelo en Cloud AI Platform. Es un proceso de dos pasos. Primero, debemos exportar el modelo y luego implementarlo en Cloud AI Platform, que expone un a llamada REST y así para brindar predicción en línea.
Aquí la sentencia para exportar el modelo de BigQuery ML a Google Cloud Storage:
# export the model to a Google Cloud Storage bucket
bq extract -m rpm_ds.rpm_bqml_model gs://bqml_sa/rpm_data_set/bqml/model/export/V_1
En segundo lugar, debemos implementar el modelo exportado en Cloud AI Platform Prediction, que aloja el modelo entrenado, para que podamos enviar las solicitudes de predicción. Aquí se muestra el comando para implementar el modelo en Cloud AI Platform Prediction:
# export the model to a Google Cloud Storage bucket
# deploy the above exported model
gcloud ai-platform versions create --model=rpm_bqml_model V_1 --framework=tensorflow --python-version=3.7 --runtime-version=1.15 --origin=gs://bqml_sa/rpm_data_set/bqml/model/export/V_1/ --staging-bucket=gs://bqml_sa
Ahora podemos predecir en línea a través de una solicitud/respuesta web utilizando la aplicación web para realizar acciones en el momento, como mostrar contenido personalizado o activar un proceso asincrónico, como enviar un correo electrónico personalizado. A continuación se muestra el comando donde puede probar rápidamente la predicción en línea:
# Perform online predict (create a input table with the input features)
# create a json file (input.json) with the below content
{"bounces": 0, "time_on_site": 7363}
# use the above json to predict
gcloud ai-platform predict --model rpm_bqml_model --version V_1 --json-instances input.json
El resultado será similar al siguiente:
Predicted results for {"bounces": 0, "time_on_site": 7363} is PREDICTED_WILL_BUY_ON_RETURN_VISIT WILL_BUY_ON_RETURN_VISIT_PROBS WILL_BUY_ON_RETURN_VISIT_VALUES
['1'] [0.9200436491721313, 0.07995635082786867] ['1', '0']
En el resultado anterior, el modelo predijo que este cliente en particular tiene la propensión a comprar ya que PREDICTED_WILL_BUY_ON_RETURN_VISIT devuelve 1. Dada esta prueba de” 0 “rebotes y” 7363 “segundos en time_ont_site, el modelo nos dice que hay un 92% posibilidad de que tengan la propensión a comprar. Con esta información, podemos enviarle un cupón al cliente (o quizás solo queremos regalar cupones a clientes entre 0.5 y 0.8 de probabilidad, porque hay una alta probabilidad de que compren el artículo también sin incentivos).
Por supuesto, podemos utilizar otras herramientas además de gcloud, por ejemplo (wget, curl, postman, etc.) para verificar rápidamente el endpoint del tipo REST.
4. Unificar a los datos del cliente con un sistema CRM para recopilar detalles del cliente (por ejemplo, identificación de correo electrónico, otras informaciones del cliente, etc.)
Por lo tanto, ahora podemos predecir si un cliente tiene la propensión a comprar por lotes o en línea. ¿ Y que viene ahora? Bueno, estamos usando fullvisitorid en el conjunto de datos. Necesitaremos los detalles del cliente, como la dirección de correo electrónico, porque su conjunto de datos no los tiene. La idea es recopilarlos de un sistema de gestión de relaciones con el cliente (CRM). Por lo tanto, necesitamos integrarnos con un sistema CRM para lograr el objetivo.
Si estamos utilizando Google Analytics y GA4 versión free, hay que realizar una tarea de *matchin* para ello utilizaremos una hoja de cálculo, en caso de integración con Salesforce, será disponible en GA360. El artículo habla sobre cómo integrar la Google Analytics 360 con Salesforce Marketing Cloud. La integración permite publicar audiencias creadas en Analytics 360 en Marketing Cloud y utilizar esas audiencias en las campañas de marketing directo por correo electrónico y SMS de Salesforce. Debemos determinar el mecanismo de integración adecuado en función de su plataforma CRM.
Restos de pasos de las solución: desde el 5 hasta el último
El resto de los pasos de la solución se explican por sí mismos, aunque puede que no sea tan trivial integrar e interoperar los sistemas. Pero, bueno, ese es un desafío continuo en el ciclo de vida del desarrollo de software en general, ¿no es así? También podemos consultar algunas pautas a medida que los próximos pasos potenciales continúan basándose en la solución existente.
Automatización y creación de un pipeline de Machine Learning
Ahora vamos a crear un pipeline de machine learning para automatizar la solución de los pasos descritos de 1 a 3. Para ello utilizaremos Kubeflow Pipelines (KFP) y KFP administrado, Cloud AI Platform Pipelines en Google Cloud.
A continuación se muestra la representación visual de los pasos de la solución, que están disponibles en el mismo notebook en github visto anteriomente.
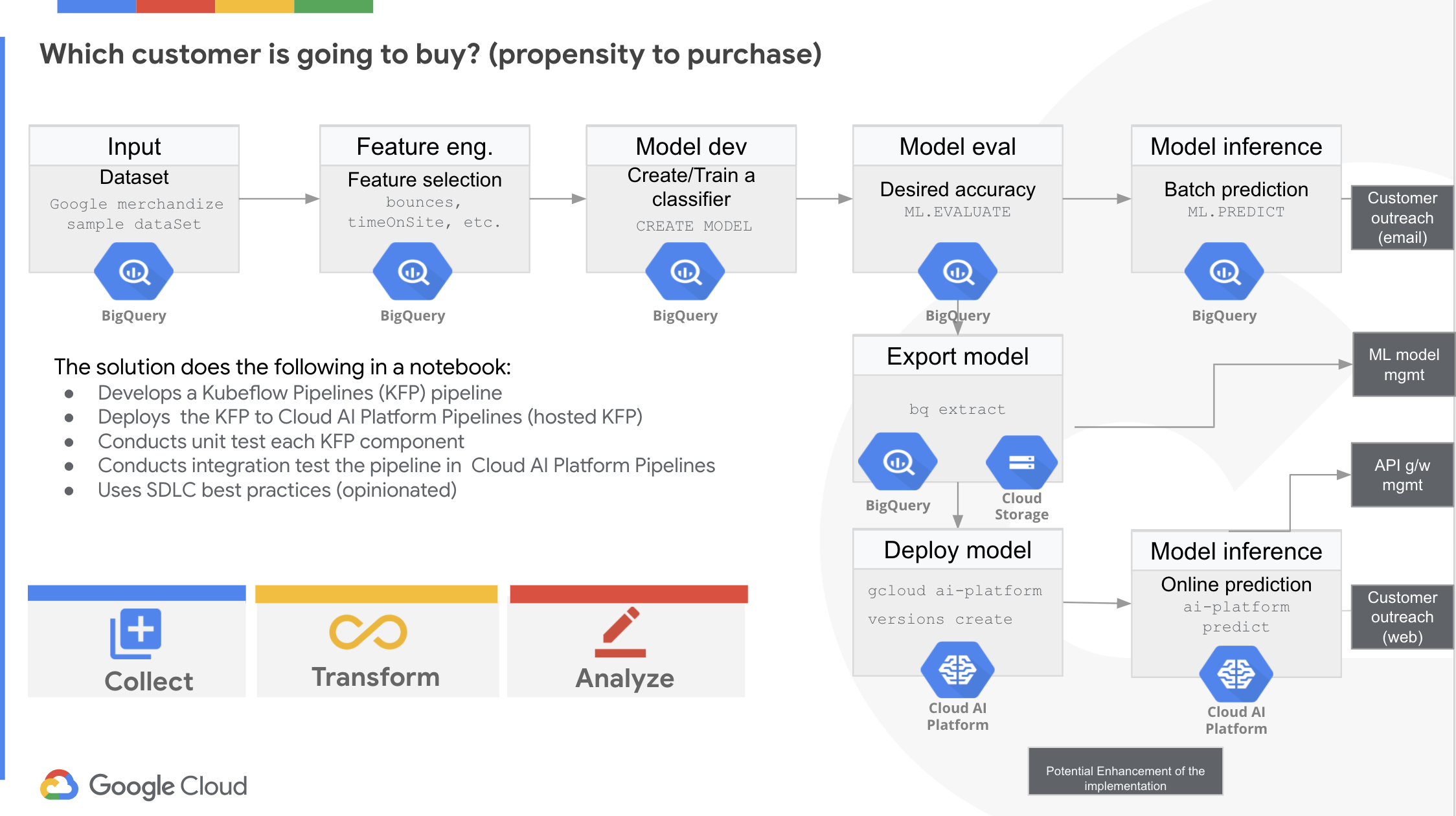
A continuación se muestra la representación visual de los pasos de las soluciones que se basan en la implementación actual:
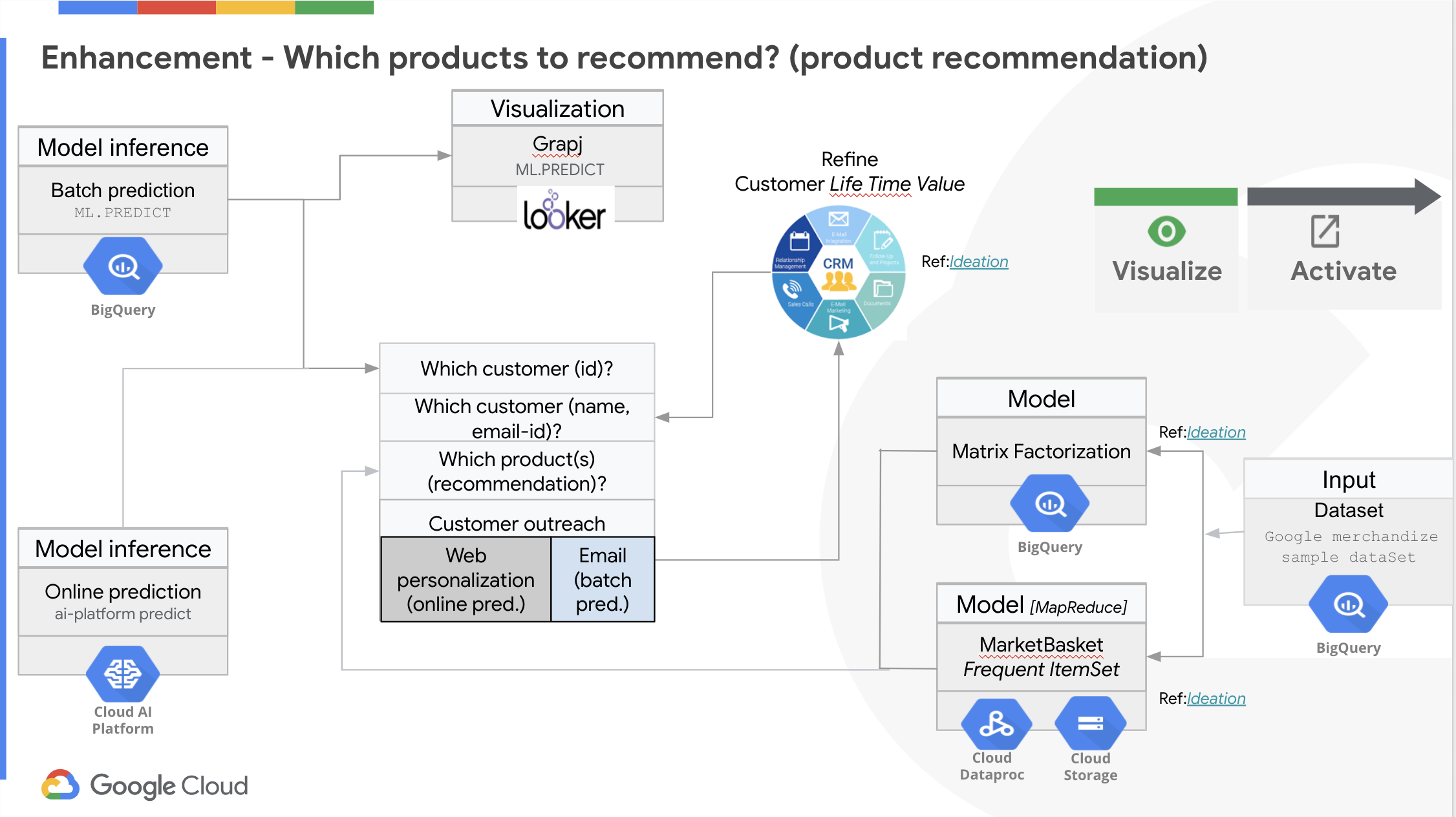
Los tres enlaces en los diagramas anteriores son:
- Consulte el artículo para tener una idea sobre cómo utilizar los clientes que tienen propensión a comprar con un sistema CRM.
- Consulte el artículo, para obtener una idea de cómo puede utilizar Matrix Factorization para recomendar productos indicado en este documento
- Consulte el Capítulo 6 “Conjuntos de elementos frecuentes” del libro “Minería de conjuntos de datos masivos” escrito por un profesor de la Universidad de Stanford, para tener una idea de cómo crear una lista de productos de uso frecuente.
A continuación, se muestra el resultado de Cloud AI Platform Pipelines cuando ejecutamos el experimento de KFP desde el notebook. Cuando ejecutamos el experimento, es muy probable que resultado no sea el mismo:
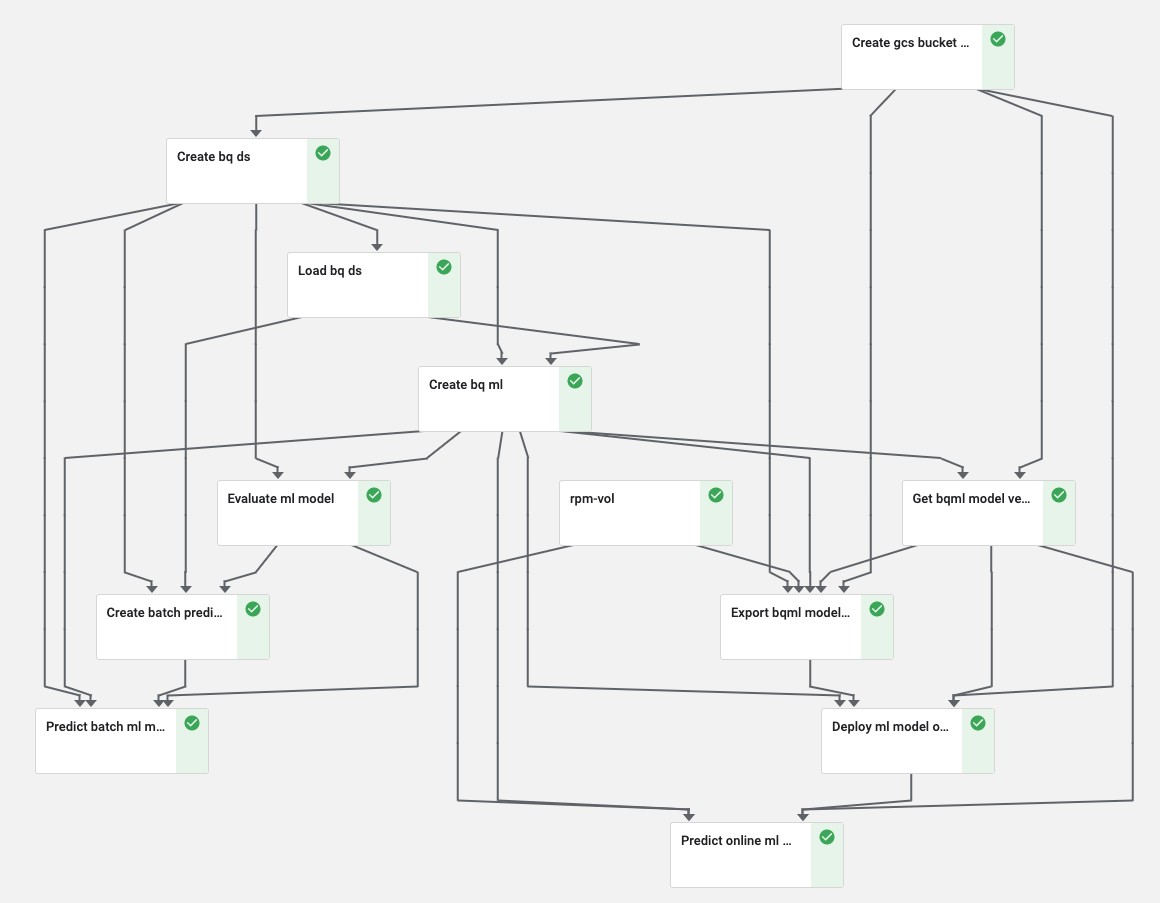
Cada cuadro representa un componente de KFP. Puedes consultar el notebook de jupyter anterior para conocer la semántica, la sintaxis, el paso de parámetros en la función, etc.
* Environment Setup
- Setup Cloud AI Platform Pipelines (using the CloudConsole)
- Install KFP client
- Install Python packages for Google Cloud Services
* Kubeflow Pipelines (KFP) Setup
- Prepare Data for the training
-- Create/Validate a Google Cloud Storage Bucket/Folder
-- Create the input table in BigQuery
- Train the model
- Evaluate the model
- Prepare the Model for batch prediction
-- Prepare a test dataset (a table)
-- Predict the model in BigQuery
- Prepare the Model for online prediction
- Create a new revision (for model revision management)
-- Export the BigQuery Model
-- Export the Model from BigQuery to Google Cloud Storage
-- Export the Training Stats to Google Cloud Storage
-- Export the Eval Metrics to Google Cloud Storage
- Deploy to Cloud AI Platform Prediction
- Predict the model in Cloud AI Platform Prediction
* Data Exploration using BigQuery, Pandas, matplotlib
* SDLC methodologies Adherence (opinionated)
- Variables naming conventions
-- Upper case Names for immutable variables
-- Lower case Names for mutable variables
-- Naming prefixes with rpm_ or RPM_
- Unit Tests
- Cleanup/Reset utility functions
* KFP knowledge share (demonstration)
- Pass inputs params through function args
- Pass params through pipeline args
- Pass Output from one Component as input of another
- Create an external Shared Volume available to all the Comp
- Use built in Operators
- Built light weight Component
- Set Component not to cache
Próximos pasos
Existen una serie de mejoras o alternativas que podemos utilizar para su caso de uso específico. Por ejemplo, hemos utilizado la regresión logística en este artículo pero podríamos utilizar XGBoost u otros. También podemos entrenar varios modelos en paralelo y luego evaluar para decidir qué modelo funciona mejor para su escenario. Alternativamente podemos utilizar el pipeline de MLOps y dejar que BigQuery haga el trabajo pesado para encargarse de los cálculos necesarios para entrenar los modelos. Y hay mucho más.
Ahora que tenemos el endpoint para la predicción en línea, podemos publicar la API en un desarrollo web, app y/o monitorear su uso. Una de los servicios a utilizar en este ejemplo es Google Apigee, una plataforma de administración de API, por ejemplo.
Determinar qué producto(s) debemos recomendar al cliente
Una vez que determinamos qué cliente tiene la propensión a comprar, necesitamos averiguar qué producto(s) deberíamos recomendarles. Podríamos lanzar una campaña que utilice mensajes personalizados para una base de clientes específica. Hay muchos enfoques para determinar los productos que deberíamos recomendar al cliente. Puede utilizar una técnica de Factorización de matrices o utilizando el Market Basket Analysis que como vimos anteriormente se utilizará el FrequentItemSet como punto de partida.
El modelo MarketBasket también podría proporcionar un modelo de predicción de estado en línea, es decir, cuando un cliente busca (o cualquier acción equivalente como agregar al carrito de compras) el Producto A, entonces usted podría recomendar el siguiente Producto B y así sucesivamente. Como ejemplo viene utilizado uno de los estudios más interesantes, el propio cap6 del material proporcionado antes, en particular para un retail muy conocido en EEUU, se descubrió si alguien está comprando pañales, es posible que desee recomendarles que compren cerveza. O si un cliente ha agregado tierra para macetas a su carrito, podría recomendarles comida veggie. Cuanto mejor conozca la intención del cliente, mejor podrá recomendar otros productos pertinentes. Las opciones son infinitas …y actualmente mucho retail ya lo están poniendo en práctica, (Amazon, por ejemplo).
Conclusiones
Y llegamos al final de este largo post. Aprendimos a crear un modelo de propensión con BigQuery ML y cómo organizar una flujo de ML en Kubeflow Pipelines. Nos faltaría estudiar mejor nuestro punto de partida, ya que tenemos disponible datos de Google Analytics, al cambiar el flujo de entrada debemos identificar otros atributos clave para nuestro modelo, el resto es cuestión de despliegue de servicios en cloud, lo mismo podemos realizarlo en AWS o Azure, hasta otros más específicos para trabajos de optimización de memoria en streaming, como Databricks. Finalmente hablamos de un solo pipeline, pero existen muchos más casos de uso. Espero que sea de utilidad este post para tu puesta en producción del modelo de machine learning aplicado a tu caso de uso y no dudes de comentar en caso estás utilizando otro similar o has tenido experiencia con Kubeflow.